在HCIP(华为认证ICT高级工程师)的数据库服务规划知识体系中,数据处理服务是核心模块之一,它直接关系到数据库能否高效、可靠地支撑上层应用。本篇笔记将围绕数据处理服务的核心概念、关键技术、规划要点及华为云相关服务进行梳理。
一、数据处理服务概述
数据处理服务是指数据库系统中负责执行数据操作(如查询、插入、更新、删除)、事务管理、并发控制、数据缓存与优化的功能集合。其目标是确保数据操作的正确性、一致性、高性能与高可用性。在云数据库架构中,数据处理服务通常作为一个独立的服务层或组件存在。
二、核心组件与关键技术
- 查询处理器:
- 查询解析与优化:将SQL语句转化为执行计划,并基于统计信息(如数据分布、索引)选择最优路径。
- 执行引擎:负责执行优化后的计划,包括数据扫描、连接、排序、聚合等操作。
- 事务管理器:
- ACID保障:通过日志(如WAL)、锁机制、多版本并发控制(MVCC)确保事务的原子性、一致性、隔离性、持久性。
- 并发控制:处理多个事务同时访问数据时的冲突,常见技术有悲观锁(行锁、表锁)和乐观锁(版本号)。
- 缓存与缓冲管理:
- 内存缓存:如InnoDB Buffer Pool,缓存热数据以减少磁盘I/O。
- 查询缓存:缓存查询结果,适用于读多写少的场景(注意:MySQL 8.0已移除查询缓存)。
- 存储引擎接口:
- 提供与底层存储(如硬盘、SSD)交互的抽象层,支持多种引擎(如InnoDB、MyISAM)。
三、规划要点
- 性能规划:
- SQL优化:避免全表扫描、合理使用索引、减少JOIN复杂度。
- 硬件资源配置:根据业务负载(OLTP/OLAP)配置足够的CPU、内存(特别是缓存大小)、高速存储(如NVMe SSD)。
- 连接池管理:控制并发连接数,避免资源耗尽。
- 高可用与容灾:
- 主从复制:通过异步/半同步复制实现读写分离与故障切换。
- 自动故障转移:结合监控与集群管理工具(如Keepalived、MHA)实现快速恢复。
- 扩展性设计:
- 读写分离:将读请求分发到只读副本,减轻主库压力。
- 分库分表:对于海量数据,可采用水平拆分(如按用户ID哈希)分散负载。
- 安全与合规:
- 数据脱敏:对敏感字段(如手机号、身份证)进行加密或模糊处理。
- 审计日志:记录所有数据操作,便于追溯与合规检查。
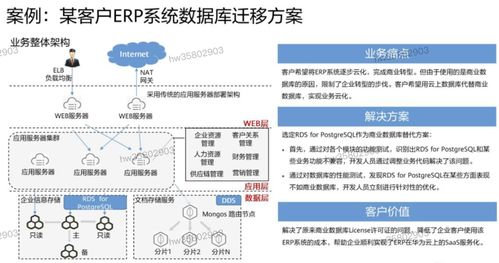
四、华为云数据处理服务实践
华为云提供了一系列数据库相关服务,助力企业构建高效的数据处理体系:
- 云数据库RDS:支持MySQL、PostgreSQL等主流引擎,内置自动备份、监控告警、读写分离等功能。
- 分布式数据库DDM:实现自动分库分表,对应用透明,轻松应对数据量增长。
- 数据复制服务DRS:支持异构数据库迁移与实时同步,降低数据流动成本。
- 数据库安全服务:提供数据加密、防SQL注入、敏感数据发现等安全能力。
五、
数据处理服务是数据库系统的“大脑”,其规划需紧密结合业务特征(如事务型、分析型)、数据规模、性能要求及成本约束。在云时代,利用华为云等平台提供的托管服务,可以大幅降低运维复杂度,但深入理解底层原理仍是优化性能、排查故障的基石。建议在HCIP备考与实际工作中,多结合场景进行设计与调优实验,以巩固理论知识。